How do we crawl the internet?
Our in-house experts developed and maintain our very own web-crawling spiders. Each month, these index the entire internet of over 700 million domains, structuring the data for you to utilize. Curious if we've crawled your website? Identify our spiders by the reverse DNS: if you find 'dataproviderbot.com', you're a part of the network.
Request a free demoOur Dataprovider.com spider
What a crawler sees vs what a human sees
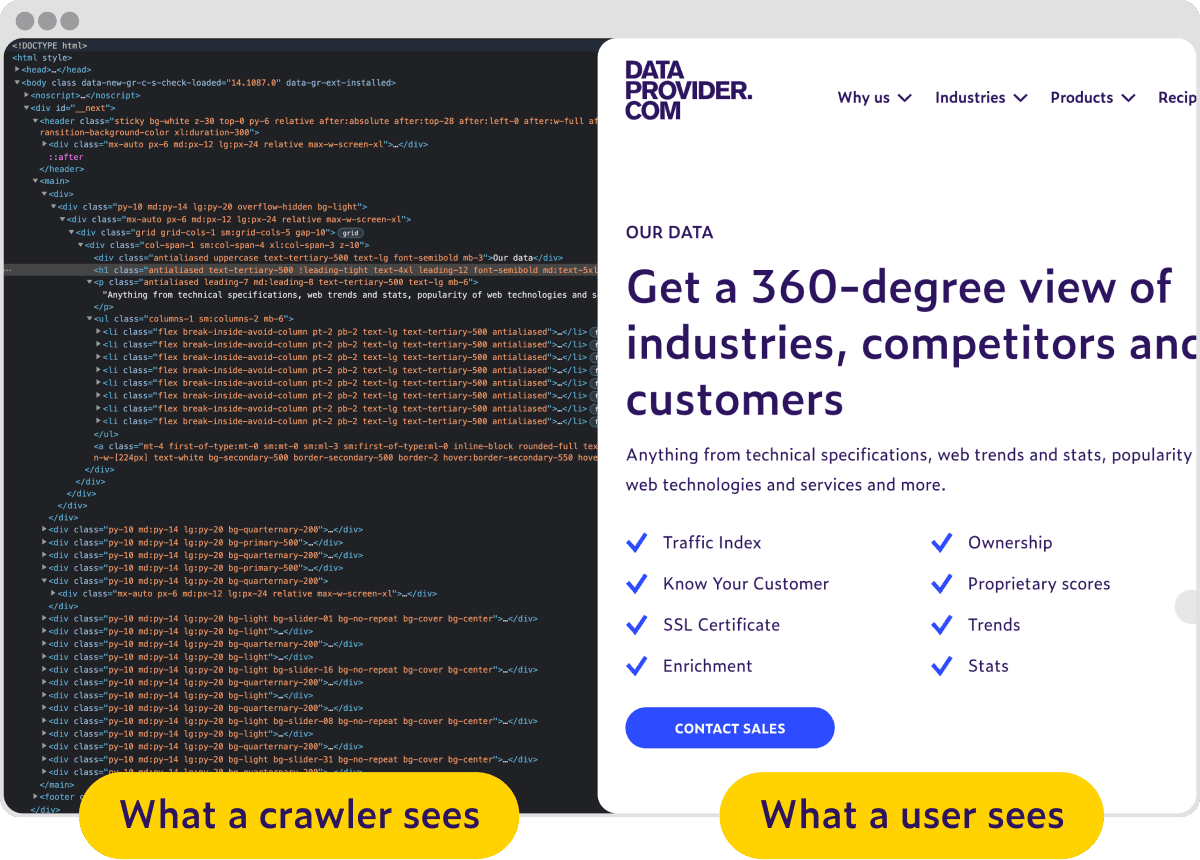
In-house developed
At Dataprovider.com we use our own in-house developed spider to analyze domains. To avoid inconvenience and save bandwidth our spider works very efficiently. The Dataprovider.com spider identifies itself with a user agent, which makes it visible in logs and site statistics programs you may use. Look for the following agent:
"Mozilla/5.0 (compatible; Dataprovider.com)"Robot Exclusion Protocol
The robot exclusion protocol is a set of instructions that specifies which areas of a website a robot can and cannot process. We adhere to these instructions and exclude any directory or content that does not want to be indexed. There are two way’s to instruct a spider not to index your website. You can use a META tag in the HMTL, or alternatively add a robots.txt to the root folder of your web site.
Robots META tag
In the HTML of a page you can add a robots META tag. With the META tag, a robot can be instructed whether or not to index a given webpage, and whether or not to follow the links to another page. If you want to exclude pages of your website from indexation, you can imbed the robot META tag as shown in the following HTML code:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="robots" content="noindex, nofollow">
</head>Robots.txt file
The robot exclusion protocol uses the robots.txt file, which is required to be placed in the root directory of a site. For example: if you have the website mydomain.com you can create a file called mydomain.com/robots.txt. Before the spider indexes any website, it will always look for this file. The Dataprovider.com spider is triggered by setting the user-agent to ‘dataprovider’ (if you only want to disallow dataprovider.com) or to ‘*’ if you want to disallow all spiders.
User-agent: dataprovider
Disallow: /For more information on how to block spiders check http://www.robotstxt.org/robotstxt.html
Alternatively, you can contact us and opt out by filling in the form.
Start today
Whether you need actionable web data insights for day-to-day projects or for long-term strategies, the answer to your question lies in our structured web data.